ما هي آلية عمل ChatGPT؟ شرح مُبسّط وشامل لروبوت الدردشة الجديد
هناك تشابه من ناحية المبدأ بين محرك بحث غوغل وروبوت الدردشة ChatGPT. فكلاهما يمكنك التواصل معه من خلال سطر واحد من المُدخلات النصية. ولكن غوغل يعطيك مجموعة من نتائج البحث على شكل مقالات وصفحات ويب ذات علاقة بكلمة البحث التي استخدمتها.
بينما على العكس فإن ChatGPT يحلل سياق الكلمات المُدخلة محاولاً فهم قصدك عند كتابة هذا السطر، ومن ثم يزوّدك بردٍ مناسب وإجابة شاملة لسؤالك. لا يمكنك على سبيل المثال الطلب من غوغل كتابة قصة قصيرة أو كود برمجي من الصفر، ولكن ChatGPT يمكنه القيام بكل ذلك.
تكمن ميزة غوغل في قدرته على البحث في ملايين قواعد البيانات وإعطائك أقرب النتائج لكلمة البحث. أما ChatGPT فتكمن قوته في قدرته على تحليل كلمات البحث من كافة الجوانب وإنتاج إجابة مخصصة لطلبك بناءً على المعلومات الموجودة في شبكة الإنترنت.
سنشرح في هذا المقال الآلية التي يتبعها ChatGPT لإنتاج هذه الإجابات بالتفصيل وبأسلوب مبسّط ونجيب عن بعض الأسئلة التي من المؤكد أنها خطرت على بالك عند استخدام هذه الأداة.
الخطوتان الرئيسيتان اللتان يتبعهما ChatGPT
دعونا نستخدم محرك البحث غوغل للمقارنة مرة أخرى. عندما تطلب من غوغل البحث عن شيء معين فإنه في الحقيقة لا يبحث لحظتها في شبكة الإنترنت عن طلبك، وإنما يبحث في قواعد البيانات التي يخزّنها عن صفحات ذات صلة بكلمة البحث المُستخدمة. وهكذا فإن آلية عمل غوغل يمكن تلخيصها في خطوتين أو مرحلتين هما:
مرحلة الزحف spidering والأرشفة data gathering وفيها يتم التعرف على صفحات الويب وتخزين محتواها في قواعد بيانات ضخمة جداً
مرحلة التفاعل مع المستخدم والبحث عن طلبه ضمن قواعد البيانات هذه
يمكننا تشبيه آلية عمل ChatGPT بآلية عمل غوغل. فالخطوة الأولى في ChatGPT تُدعى بالتدريب المُسبق pre-training أما الخطوة الثانية فتُدعى inference أو التحليل واستنتاج الإجابة والتفاعل مع المستخدم.
يعود سبب تطوّر مجال الذكاء الاصطناعي التوليدي Generative AI مؤخراً بسرعة كبيرة فجأةً إلى تطوّر المرحلة الأولى pre-training وزيادة إمكانياتها بشكل مهول بفضل تنامي إمكانيات الأجهزة الهاردوير والحوسبة السحابية.
كيف تعمل خطوة التدريب المُسبق pre-training في
تقنيات الذكاء الاصطناعي التوليدي
يتم ذلك وفق آليتين أحدهما خاضعة للإشراف supervised والأخرى غير خاضعة للإشراف non-supervised. حيث تدربت معظم تقنيات الذكاء الاصطناعي التوليدي حتى يومنا هذا -على الأقل جزئياً- بواسطة الآلية الخاضعة للإشراف.
في هذه الآلية يتم تدريب نموذج الذكاء الاصطناعي على مجموعة من البيانات المنظمة في جداول والمترابطة، بحيث يرتبط كل مُدخل بمُخرج مُحدد ومعروف.
فعلى سبيل المثال يتم تدريب الذكاء الاصطناعي على مجموعة بيانات لمحادثة بين زبون وموظفة خدمة العملاء. حيث تكون أسئلة وشكاوي الزبون مرتبطة برد مناسب من قبل الموظفة، وتُعتبر أسئلة الزبون هي المُدخلات والإجابات هي المُخرجات.
يتم تدريب التقنية على ربط المُدخل (على سبيل المثال سؤال الزبون “كيف يمكنني إعادة تعيين كلمة المرور”) بالمُخرج المناسب وليكن مثلاً: “يمكنك إعادة تعيين كلمة المرور من خلال الدخول لصفحة إعدادات الحساب واتباع التعليمات.”
وفق آلية التدريب الخاضعة للإشراف تتعلم تقنية الذكاء الاصطناعي ربط المُدخلات بالمُخرجات الصحيحة، وبالتالي تتعلّم عدّة وظائف منها التصنيف classification (ويعني ذلك تصنيف الطلب أو الملاحظات الجديدة وفق صفات محددة، مثلاً تصنيف الأسئلة إلى طلبات مهذبة وغير مهذبة)، وregression (وهذا يعني التنبؤ بالقيم في مجال متسلسل منها) وغيرها من المهارات.
لا شك أن آلية التدريب هذه محدودة جداً. إذ يتوجب على البشر تزويد الآلة بكل المُدخلات والمُخرجات التي تخطر على البال. وبالتالي فإن عملية التدريب ستستغرق وقتاً طويلاً ولن تكون شاملة تماماً لكل المُدخلات والمُخرجات المُمكنة، بل ستكون هذه المُدخلات والمُخرجات مقتصرة على المجال الذي يختص به الشخص الذي يشرف على تدريب الآلة.
ولكننا نعرف تماماً -من تجربتنا مع ChatGPT- أنه لا حدود له تقريباً. إذ يمكنه كتابة قصص قصيرة والإجابة عن أسئلة تخصصية في مجالات السياسة والتاريخ والرياضيات وحتى كتابة أكواد برمجية دون أن يواجه أي صعوبة في ذلك.
وبما أنه من المستحيل التنبؤ بكل الأسئلة التي يمكن أن يطرحها المستخدم على الآلة، فمن المستحيل أن يكون ChatGPT قد تدرب وفق الآلية الخاضعة للإشراف فحسب. وهنا يأتي دور التدريب غير الخاضع للإشراف non-supervised.
وفي هذه الطريقة يتم تدريب الآلة على مجموعة بيانات لا تكون فيها المُدخلات مرتبطة بأي مُخرجات محددة. وإنما تتُرك الآلة لتعلّم وتحليل بُنية المُدخلات والأنماط المختلفة فيها من دون أن يُطلب منها القيام بأي مهمة مُحددة.
باستخدام هذه الآلية تتعلّم الآلة عدة مهارات كالتجميع clustering واكتشاف الشذوذات في المجموعات anomaly detection وتقليل أبعاد البيانات dimensionality reduction. أما في مجال الذكاء الاصطناعي المعتمد على اللغة (كما في ChatGPT) فتتعلم الآلة بناء الجملة ودلالاتها، وكل ذلك بهدف تشكيل نص متماسك وذي مغزى أثناء إجراء المحادثات.
ومن هنا نفهم من أين أتت لامحدودية ChatGPT. إذ ليس من الضروري أن يعرف مطوروه كل المخرجات والمُدخلات الممكنة، وإنما كل ما عليهم فعله هو تزويد الآلة بالكثير والكثير من البيانات وتدريبها وفق هذه الآلية، وهو ما يُدعى بنمذجة لغة المحولات الأساسية transformer-base language modeling. ماذا يعني هذا؟ دعونا نبدأ بالحديث عن ما يُدعى بـ…
نماذج اللغات الكبيرة Large Language Models
يندرج ChatGPT تحت أحد أصناف نماذج معالجة اللغة الطبيعية Natural Language Processing والذي يُدعى بنماذج اللغات الكبيرة Large Language Models واختصاراً LLMs.
المهمة الأساسية التي تقوم بها LLMs هي استيعاب كميات هائلة من البيانات النصية ومحاولة إيجاد روابط أو علاقات بين الكلمات ضمن النص. تطوّرت إمكانيات هذه النماذج مؤخراً وذلك بسبب زيادة حجم البيانات التي يُمكن إدخالها بفضل زيادة إمكانيات الحوسبة السحابية.
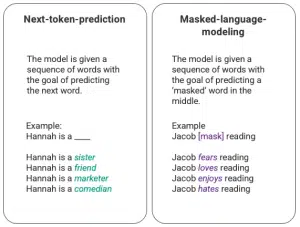
مما تتدرب عليه الآلة في LLMs التنبؤ بكلمة ضمن جملة أو في سلسلة من الكلمات، وينقسم ذلك لـnext-token-prediction أو التنبؤ بالكلمة التالية، وmasked-language-modeling أو التنبؤ بكلمة مخفية. إليك المثال التالي لتوضيح هذه الفكرة في الصورة:
تقوم الآلة (أو النموذج model) هنا بملء الفراغ بالكلمة الأكثر تناسباً مع السياق والأكثر احتمالية وفق آخر الإحصائيات، وذلك اعتماداً على نموذج يرمز له اختصاراً بـLSTM. إلّا أن هناك مشكلتان أساسيتان في طريقة التدريب هذه:
لا تستطيع الآلة إعطاء أهمية متفاوتة للكلمات المختلفة في الجمل السابقة. ففي المثال السابق على الرغم من أن كلمة reading غالباً ما تترافق مع الفعل hates إلّا أن اسم Jacob قد يكون مترافقاً مع حب القراءة أكثر من كرهها، إلّا أن الآلة قد لا تعطي أهمية أكبر لاسم Jacob بالمقارنة مع الفعل reading وبالتالي قد تختار hates بدلاً من loves.
يتم معالجة البيانات المُدخلة بشكل فردي ومنفصل بدلاً من أن تُعالج ككتلة واحدة. وهذا يقلل من احتمال إيجاد العلاقات بين الكلمات وبالتالي يقلل من المعاني التي يمكن اشتقاقها من البيانات.
في محاولةً لتجاوز هاتين المشكلتين قام فريق في Google Brain في عام 2017 بتطوير ما يُدعى بالمحولات transformers. تتفوق المحولات على نموذج LSTM بقدرتها على معالجة كل البيانات في وقت واحد. كما تستخدم ما يُدعى بـself-attention لإعطاء أهمية متفاوتة للكلمات والبيانات المُدخلة. كل هذا ساهم بتطوير كبير في نماذج اللغات الكبيرة LLMs.
معنى GPT وSelf-Attention
تمثل GPT اختصاراً لـGenerative Pre-training Transformer. لا شك أنك أصبحت الآن قادراً على فهم كل كلمة منها، فـGenerative تُشير لمجال الذكاء الاصطناعي التوليدي (أي الذي يعمل على توليد أي نوع من المحتوى وهي هنا النصوص)، وPre-training تعني التدريب المُسبق الذي شرحناه سابقاً، وTransformer هو النموذج الجديد الذي حل محل LSTM.
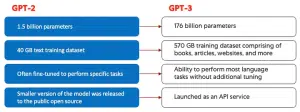
ظهرت نماذج GPT لأول مرة في عام 2018 بواسطة شركة OpenAi التي طوّرت أولى النسخ GPT-1، ثم ظهرت النسخ الأخرى GPT-2 في 2019، وGPT-3 في 2020، وأخيراً InstructGPT وChatGPT في عام 2022.
اقتصرت التطورات في نماذج GPT في الفترة الأولى على تزايد كميات البيانات التي يمكن التدرب عليها، كان هذا مدفوعاً بالتطور الحاصل في مجال الحوسبة السحابية. ونتيجة لذلك أصبحت الأجيال الأحدث من GPT ذات قاعدة معرفية أوسع بكثير وأصبحت قادرة على أداء مهام أكثر تنوعاً.
تعتمد كل نماذج GPT (كما يُشير اسمها) على المحوّلات Transformer، وهذا يعني أنها تحتوي على وحدة تشفير encoder لمعالجة المُدخلات ووحدة فك تشفير decoder لإنتاج المُخرجات. وكلاهما يحتويان على آلية multi-head self-attention لإعطاء أهمية متفاوتة لمختلف أجزاء البيانات وبالتالي استنتاج المعنى والسياق.
كما تستخدم وحدة التشفير طريقة masked-language-modeling لفهم الروابط بين الكلمات وبالتالي إعطاء إجابات مفهومة ومترابطة.
تعمل آلية self-attention على تحويل الرموز Tokens (وهي أجزاء من النص، حيث يمكن أن تكون عبارة عن كلمات أو جمل أو مجموعة من الأحرف والنصوص) إلى متجهات Vectors تمثّل أهمية هذا الرمز ضمن النص المُدخل أو التسلسل المُدخل input sequence. يتألف كل متجه من query وkey وvalue، ومن خلال عملية حسابية معقدة تعمل آلية self-attention على إيجاد العلاقة بين المتجهات.
أما تقنية multi-head فتعني أن النموذج يكرر الخطوات السابقة على أكثر من Token في نفس الوقت، وهذا يجعله قادراً على فهم المعاني الخفية والعلاقات الأكثر تعقيداً بين البيانات المُدخلة.
وعلى الرغم من أن نموذج GPT-3 حقق تطوراً ملحوظاً في معالجة اللغة الطبيعية، إلّا أنه لا يزال ضعيفاً في فهم نوايا المستخدم. حيث من الممكن أن يعطي مُخرجات:
غير مفيدة، أي أنها لا تتبع تعليمات المستخدم حرفياً.
غير واقعية أو غير منطقية أو تحتوي معلومات غير صحيحة.
لا يمكن فهمها أو تفسيرها، أي أن المستخدم لن يفهم كيف وصلت الآلة للإجابة التي زودته بها.
قد تتضمن ردوداً غير لائقة أو جارحة ومهينة للمستخدم، أو منحازة سياسياً أو دينياً، أو تحتوي على معلومات ضارة أو مغلوطة.
ولكن ما سبب حدوث هذه المشاكل؟
يعود ذلك أساساً لأن البيانات التي تستخدمها الآلة لتتعلم منها وفق طريقة التدريب pre-training قد تكون هي أساساً منحازة أو تحتوي معلومات خاطئة. ولهذا السبب فإن الشركات التي تطبق هذه النماذج تُنشئ ما يُدعى بـ”حواجز حماية”. إلّا أن هذه الحواجز بحد ذاتها قد تسبب انحيازاً في المعلومات المقدّمة لأنها تمثل وجهة نظر الشخص أو الجهة التي أنشأتها والتي قد تعتبر انحيازاً بالنسبة لغيرها.
وهذا يجعل تصميم روبوت محادثة عالمياً صعباً نتيجة الطبيعة المُعقدة للمجتمعات البشرية. تم في ChatGPT تقديم منهجيات جديدة في محاولة لتجاوز هذه المشاكل المتأصلة في LLMs.
ولكن ما هي البيانات التي اعتمد عليها ChatGPT في عملية تدريبه؟
مجموعات البيانات التي تدرّب عليها ChatGPT
يعتمد ChatGPT أساساً على النسخة السابقة من هذا النموذج GPT-3. وقد تدرّب نموذج GPT-3 على مجموعة بيانات تُدعى بـWebText2، وهي مكتبة ضخمة تحوي أكثر من 45 تيرابايت من البيانات النصية. يمكنك تخيّل حجم البيانات التي تدرّب عليها GPT-3 على اعتبار أن النصوص تستهلك قدراً صغيراً جداً من المساحة التخزينية، فما بالك بـ45 تيرابايت!
هذه الكمية الضخمة من البيانات سمحت لـChatGPT بتعلّم العلاقات بين الكلمات والجمل وأنماطها والكثير من تفاصيل “اللغة الطبيعية” بسرعة ودقّة. وهذا ما جعله فعالاً جداً في إنتاج محتوى متناسق ومفهوم ومناسب لطلبات المستخدم.
ذكرنا أن ChatGPT يعتمد على GPT-3، إلّا أنه خضع لتحسينات وتطويرات كثيرة حسّنت من أدائه كثيراً في المحادثات. وأعطى ذلك تجربة أكثر تخصيصاً وجاذبية للمستخدم الذي يتفاعل مع الآلة من خلال واجهة الدردشة.
فعلى سبيل المثال أطلقت شركة OpenAI مجموعة بيانات Persona-Chat مصممة خصيصاً لتدريب نماذج الذكاء الاصطناعي التي تعتمد على المحادثات. وتتألف من أكثر من 160000 حوار بين شخصين حقيقيين، بحيث يتسم كل منهما بشخصية محددة يتحدث عنها المشارك واصفاً اهتماماته وشخصيته وتجاربه السابقة. يسمح ذلك لـChatGPT بتعلم كيفية إنتاج إجابات مخصصة ومناسبة لسياق المحادثة وشخصية المستخدم.
هناك الكثير من مجموعات البيانات التي استخدمت لتدريب ChatGPT، ومنها
بالإضافة لما سبق فقد تدرب ChatGPT على كمية كبيرة من البيانات غير المنظّمة الموجودة على الإنترنت، بما في ذلك مواقع الويب والكتب وغيرها، وسمح ذلك بتعلّمه أنماط اللغة العامة المستخدمة في الإنترنت. إلّا أن معظم البيانات المستخدمة في تدريب ChatGPT مستخلصة من محادثات بهدف تخصيصه لأمور المحادثة.
وهكذا يمكن أن نفهم أن تدريب ChatGPT تم من خلال تزويده بكميات كبيرة من البيانات غير الخاضعة للإشراف وتركه ليتعلّم منها ويستنتج ويفهم خواص اللغة وأنماطها واستخداماتها.
ماذا عن مشاركة البشر في مرحلة التدريب المُسبق؟
مما سبق يُمكننا أن نفهم أن عملية pre-training لا تتطلب جهداً بشرياً، إذ تُعطى الآلة كمية كبيرة من البيانات وتُترك لتتعلم منها.
إلّا أن تقريراً في مجلة TIME أشار لمشاركة البشر في فحص البيانات وعزل أي بيانات ضارة أو مؤذية استخدمت في تدريب ChatGPT.
كما أشار تقرير في مجلة Martechpost إلى أن نموذج LLM تم تدريبه بالاستعانة بـReinforcement Learning from Human Feedback (RLHF)، أي أن للبشر دور في تزويد الآلة بتقييم لإجاباتها على شكل عقوبات أو مكافآت بهدف تحسين أدائها في المحادثات خصوصاً.
وعند سؤال ChatGPT نفسه فسيؤكد هذا، وبالتالي يمكننا القول أن البشر ساهموا مباشرةً في عملية تحسين ChatGPT.
على الرغم من أن الخطوة الأولى المتمثلة بالتدريب المُسبق هي الأضخم، إلّا أنه ما زال على ChatGPT فهم طلبات المستخدم وإنتاج ردود مناسبة. وهذه هي الخطوة الثانية المتمثلة في التفاعل مع المستخدم inference والتي تتضمن معالجة اللغة الطبيعية وإدارة المحادثة.
معالجة اللغة الطبيعية Natural language processing وChatGPT
ذكرنا هذا المصطلح سابقاً ولكن ما الذي يعنيه حقاً وما علاقته بـChatGPT؟
يهتم مجال معالجة اللغة الطبيعية NLP بتمكين الحواسيب والآلات من فهم كلام البشر وتفسير مقاصده ومن ثم إنتاج نصوص مشابهة لهذا الكلام (أو ما يُدعى باللغة الطبيعية). ويُعد هذا المجال من المجالات المتطورة بسرعة والهامة جداً مؤخراً.
يمكن استخدام تقنيات NLP في العديد من التطبيقات كبوتات الدردشة وتحليل المشاعر والتعرف على الكلام والترجمة. حيث تستخدم الشركات هذه التقنيات لأتمتة المهام وتحسين تجربة المستخدم.
من التحديات التي تواجه هذا المجال التعامل مع تعقيدات وغموض اللغة التي يستخدمها البشر. إذ يتوجب تدريب تقنيات NLP على الكثير من البيانات لتتمكن من استنتاج الأنماط وتعلم الفروق الدقيقة بين مقاصد اللغة. كما يتوجب تحديثها باستمرار بسبب ظهور تطورات جديدة دوماً على اللغات.
تعمل تقنيات NLP على تجزئة الجمل والفقرات إلى وحدات أصغر ومن ثم محاولة إيجاد روابط بينها وفهم معانيها. وتستخدم NLP لذلك تقنيات النمذجة الإحصائية statistical modeling والتعلم الآلي machine learning والتعلم العميق deep learning.
إدارة الحوار
لربما لاحظت أن ChatGPT يطرح أحياناً أسئلة لمتابعة طلبك والاستفهام عن قصدك وبالتالي إعطائك إجابة مخصصة ومناسبة لك، آخذاً بعين الاعتبار محادثتك السابقة معه.
يمكن لـChatGPT من خلال ذلك جعل المحادثة تبدو طبيعية وجذابة. مستخدماً خوارزميات وتقنيات التعلم الآلي لفهم سياق المحادثة والمحافظة عليها خلال مراحل المحادثة المختلفة.
تعد إدارة الحوار من الجوانب الهامة في NLP لأنها تسمح للحواسيب بالتفاعل مع البشر بطريقة أشبه بالمحادثة بدلاً من أن تكون عبارة عن سؤال وجواب. تكمن أهمية ذلك في أنه يزيد ثقة المستخدم وتفاعله مع الآلة، وبالتالي يعطي نتائج أفضل سواءً للمستخدم أو للمؤسسة التي تستخدم البرنامج.
نظرة في الهارد وير الذي استخدم لتشغيل ChatGPT
نشرت مايكروسوفت مؤخراً فيديو يوضح كيف استخدم Azure لتشكيل شبكة لتشغيل جميع عمليات الحوسبة والتخزين السحابي لتشغيل ChatGPT.
بعض الأسئلة الشائعة عن ChatGPT
لماذا تبدو إجابات ChatGPT واقعية وحقيقية فعلاً؟
لأن النموذج تدرّب باستخدام كميات هائلة جداً من البيانات والمحادثات التي أجراها وكتبها بشر حقيقيون، لذا فإن ردوده قد تبدو مشابهة لكلام البشر الحقيقي.
هل يمكنني الوثوق بـChatGPT للحصول على إجابات واقعية وصحيحة؟
ChatGPT لا يتصل بالإنترنت، وبالتالي فإن المعلومات التي يُقدّمها قد تكون أحياناً غير صحيحة. كما أن معلوماته عن العالم بعد عام 2021 محدودة. ويمكن أيضاً أن يُعطي إجابات منحازة أو محتوىً ضاراً. لذا يُنصح بعدم استخدام إجاباته مباشرة دون تحقق من صحتها.
يمكن أحياناً أن يُعطي البرنامج جواباً لا علاقة له بالسؤال المطروح.
هل تطّلع OpenAI على المحادثات المُجراة باستخدام ChatGPT؟ وهل ستستخدم لتدريب البرنامج؟
نعم، وذلك بغرض تحسين البرنامج وضمان توافق المحتوى المُقدّم مع سياسة الشركة ومتطلبات الأمان والسلامة.
كما يتم مراجعة المحادثات التي أجريتها مع ChatGPT بغرض تحسين الخدمة.